Claude’s Mythos Model: Speculations on Byte’s Seed Technology
The Claude Mythos model, rumored to be incredibly powerful, has raised questions about its potential use of technology from Byte.
This “strong enough not to be publicly released” Mythos model has stimulated imaginations regarding the next generation of LLM architecture.
The community is actively discussing whether it employs a Looped Language Model architecture, a concept stemming from a paper produced by the Byte Seed team in collaboration with several universities, with contributions from Yoshua Bengio.

Key clues lie in a set of test data released by Anthropic. The Byte paper indicates that graph search is one of the areas where the looped algorithm has a significant theoretical advantage over standard RLVR.
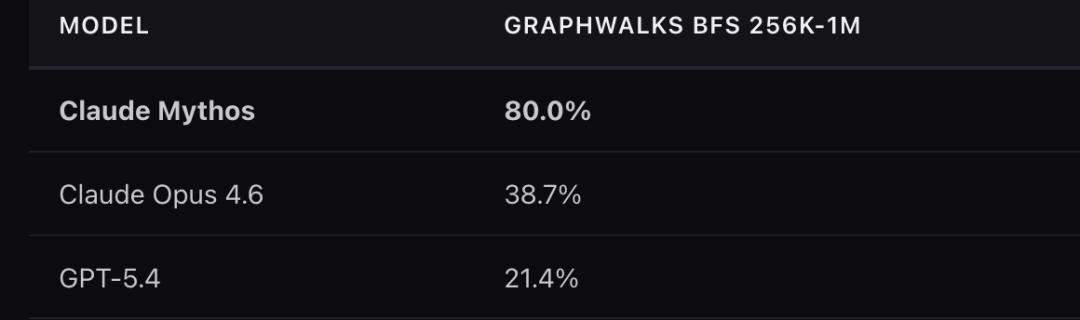
Looking at Mythos, it has surpassed its competitor GPT-5.4 by a notable margin in the breadth-first search test, GraphWalks BFS.
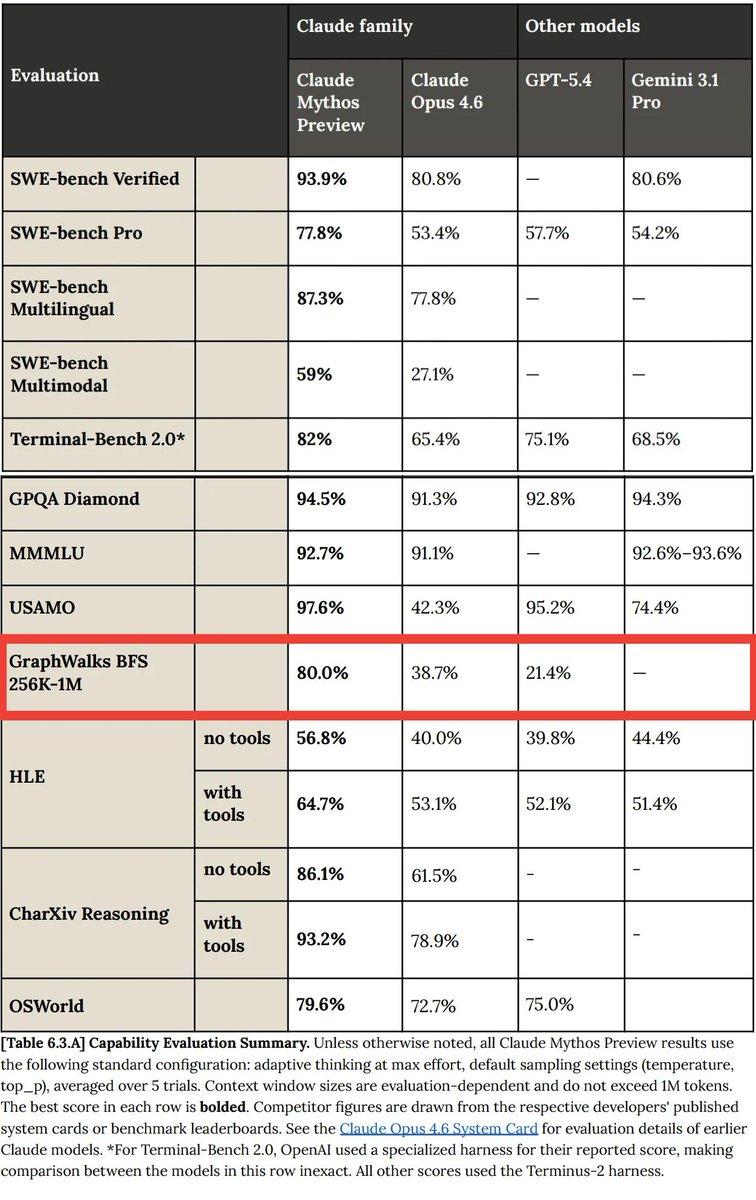
With scores of 80% to 21%, this represents a nearly fourfold difference. In other types of tasks, such a significant score disparity does not appear, suggesting that this advancement likely stems from architectural innovation rather than general Scaling Law improvements.
Looped Language Model: Iterative Processing in the Same Layer
The GraphWalks BFS test involves providing the model with a complex graph structure to perform breadth-first searches, starting from a point and layer by layer visiting all adjacent nodes. Standard Transformers can only process such problems with a single forward pass, moving from start to finish without the concept of “iteration”.
Mythos achieved an 80% score in graph traversal, indicating that it likely engages in “repeated calculations,” processing the same set of information multiple times.
So, what kind of architecture allows for “repeated calculations”? The Byte Seed team proposed the LoopLM (Looped Language Model) in their paper.
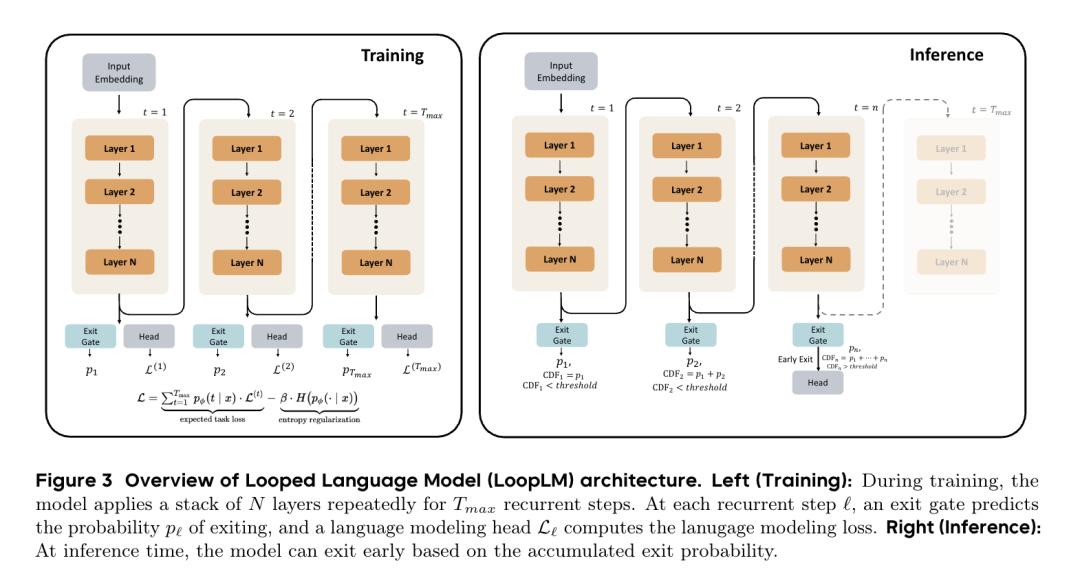
In summary, LoopLM has three characteristics:
1. No lengthy written thoughts; it iterates within the model’s latent space without outputting more tokens.
2. It adjusts automatically, thinking less for simple questions and more for difficult ones.
3. During pre-training, it learns “how to think in latent space” rather than just “how to predict the next token.”
In experiments, the team trained the Ouro series of looped language models, which incorporated iterative thinking.
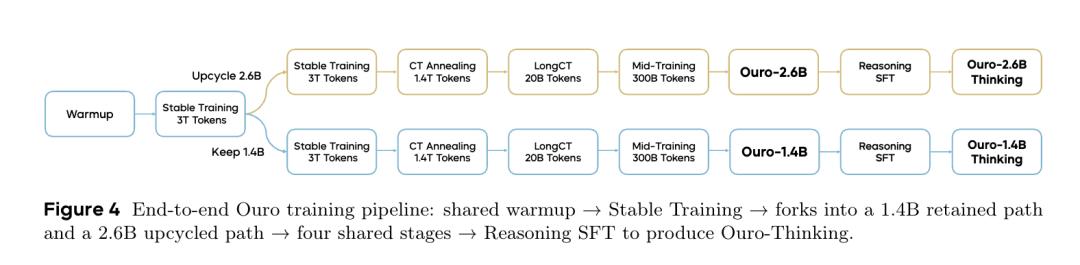
Test results showed that the 1.4B Ouro model performed comparably to a traditional model of about 4B. The 2.8B Ouro model was equivalent to traditional models of 8B-12B.
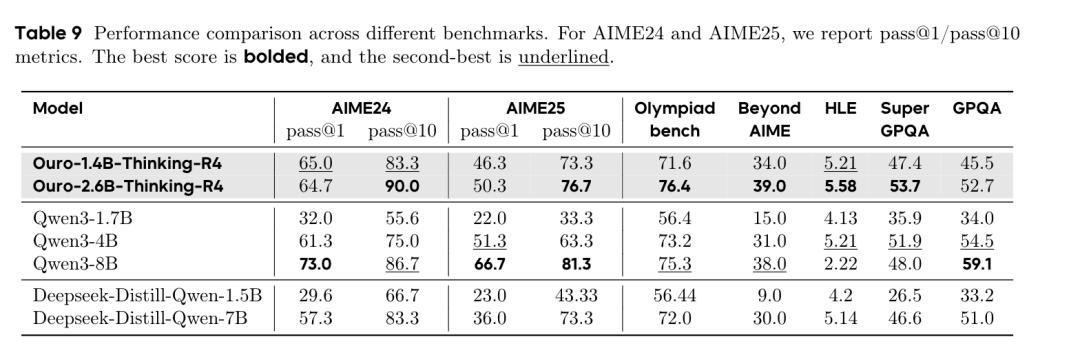
As for the source of the enhanced capabilities of the looped model, the paper analyzes the difference between Knowledge Storage and Knowledge Manipulation.
Knowledge Storage has a limited capacity, approximately 2 bits per parameter, which remains constant regardless of architecture.
However, Knowledge Manipulation allows for exponential growth in abilities like multi-hop reasoning and graph structure searches, depending on the number of loop iterations and training tokens.
In other words, the looped model does not provide AI with a larger knowledge base but significantly enhances its search and combination capabilities within that knowledge base.
So, is Mythos indeed a looped model architecture? Observers have summarized additional clues beyond GraphWalks.

Three Clues Pointing to a Looped Model Architecture
The first clue is the breadth-first graph search test results. Mythos not only scored four times higher than GPT-5.4 but also showed an unusually large improvement over the previous generation Opus.
The second clue is that Anthropic reported that Mythos uses one-fifth the number of tokens per task compared to Opus 4.6, but is slower.
(This also makes it five times more expensive!)
This is difficult to explain within a standard Transformer framework; fewer tokens should lead to faster generation steps.
However, the looped model conveniently explains this contradiction: reasoning does not occur at the token level but in the latent space, with computational effort spent in unseen areas.
The third clue is Mythos’s outstanding performance in cybersecurity.
Mythos achieved 83.1% in the CyberGym test, compared to Opus 4.6’s 66.6%, leading by nearly 17 percentage points.
Additionally, it identified thousands of zero-day vulnerabilities, leaving no mainstream operating systems or browsers unscathed.
Vulnerability discovery essentially involves traversing control flow graphs to find a path from input to dangerous functions, which is a reachability problem in graphs.
Again, this is graph traversal, a natural strength of looped architectures.
While these are merely speculations, Anthropic has not disclosed any information about the Mythos architecture and likely will not in the future.
However, one statement is worth pondering:
Scaling Law improves everything uniformly, while architectural innovations create exceptional peaks in tasks that match their inductive biases.

The inductive bias of looped Transformers is iterative graph algorithms. Mythos’s exceptional peak occurs precisely in graph traversal tasks.
The testing data speaks for Anthropic, even if they do not.
Byte paper:
https://arxiv.org/abs/2510.25741
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.